日本電信電話(NTT)は、様々な音について、それが「どんな音」であるのかを説明するテキスト(擬音語や説明文)を自動生成する技術を開発した。
マイクロホンで収録した音や録音物に対して、その音を描写した擬音語や説明文を自動生成するこの技術は、これまでの音声認識システムではテキストへの変換が困難だった人の話し声以外の様々な音を、文字に変換。見るだけでどんな音かを把握できるようになると云う。
NTTは、同技術によって、効果音や異常音などの音に基づいたメディアコンテンツの検索がより便利に。また今後、AIが人間に近い音の感覚を身につけることにも役立つとしている。

近年、音声認識技術の研究が進み、人の話し声を高い精度で認識し文字にすることが可能になってきている。
しかし、これまでの音声認識システムでは、話し声以外の様々な音を文字にすることには限界があった。また、ある音が「何の音か」を認識することを目的とした音響イベント認識の研究も近年盛んになってきているが、その音が「どんな音」で、「どう変化」しているかといった情報を擬音語や文章の形で書き出すことは難しかった。
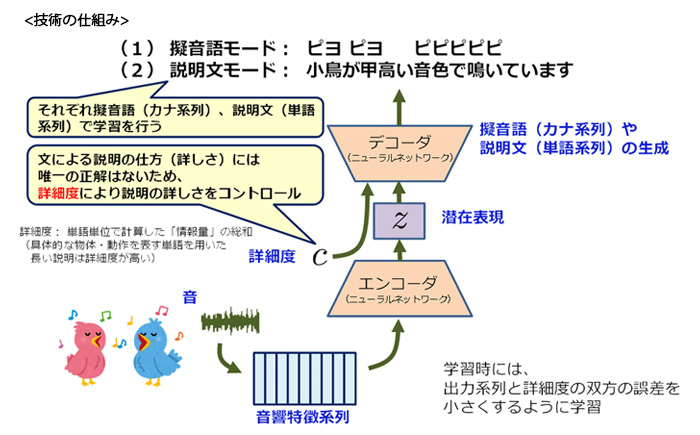
今回、NTTコミュニケーション科学基礎研究所は、多層ニューラルネットワーク(※1)に、音の特徴の時系列と文字列(擬音語)や単語列(説明文)との対応を学習させることで、音からテキストへの変換を実現した。
※1)多層ニューラルネットワーク:神経回路網をモデルとした問題解決装置。神経回路網におけるニューロンに相当するノードを多層にわたって層状に結合させ、その結合強度を変化させることで入出力の関係を学習。深層学習と呼ばれる。
[技術のポイント]
(1)音響信号から文字列や単語列への変換
開発技術は、学習段階と生成段階から成り、学習段階では、音響信号に対してどのような擬音語や説明文が当てはまるかのデータを教師データとして、多層ニューラルネットワークに学習させる。
このニューラルネットワークは、音響信号特徴の時系列を潜在特徴と呼ばれる固定次元のベクトルに変換するエンコーダ(※2)と、その潜在特徴をテキストに変換するデコーダ(※3)の、2つで構成されており、学習段階ではこれら双方を学習させる。
生成段階では、学習済みのエンコーダに音響信号特徴の時系列を入力して潜在特徴を得た後、その潜在特徴を学習済みのデコーダに入力すると、文字列が得られる仕組みになっている。
※2)エンコーダ:ここでは、高次元のデータを低次元のデータに変換する機能をもつニューラルネットワークを指す。
※3)デコーダ:ここでは、低次元のデータを高次元のデータに変換する機能をもつニューラルネットワークを指す。
(2)人手による擬音語付与よりも受容度の高い擬音語を生成
NTTは、所定の音響データセットに対して、どの程度適切な擬音語生成ができるかを評価。人手で付与した擬音語を正解とみなした客観評価実験において、単語誤り率7.2%、平均音素誤り率2.8%という結果を得た。また、生成された擬音語が人間にとってどの程度受容できるかを主観評価実験で調べたところ、78.4%の受容率が得られた。
これ受けてNTTは、結果は人手による擬音語を上回る値であり、所定の音響データに対して、同技術により概ね妥当な擬音語が生成されることが裏付けられたと結論付けている。
(3)適切な詳細度での説明文生成を実現
音に対する説明文生成では、説明の仕方(詳しさ)に絶対的な正解が存在しない。そこで、同技術では、どの程度の詳しさで説明するか指定することによって目的に適った文を生成できるよう工夫。これを条件付き説明文生成法 (CSCG法: Conditional Sequence-to-sequence Caption Generation)と呼んでいる。
条件付き説明文生成法では、詳細度(※4)と呼ばれる数値を、デコーダへの補助入力として導入。
学習段階では、詳細度の値と出力されるテキスト系列の双方の誤差が少なくなるようにし、生成段階において、音響信号と詳細度を入力し、詳細度に応じたテキストを生成する。
以上の方法により、場面や用途に合うよう、短く端的な説明や、長く詳しい説明を得ることができると云う。
※4)詳細度:デコーダの動作を制御するための補助入力値。例えば単語単位で計算した「情報量」の総和を用いることができる。具体的な物体・動作を表す単語を用いた長い説明は、詳細度の値が高くなる。
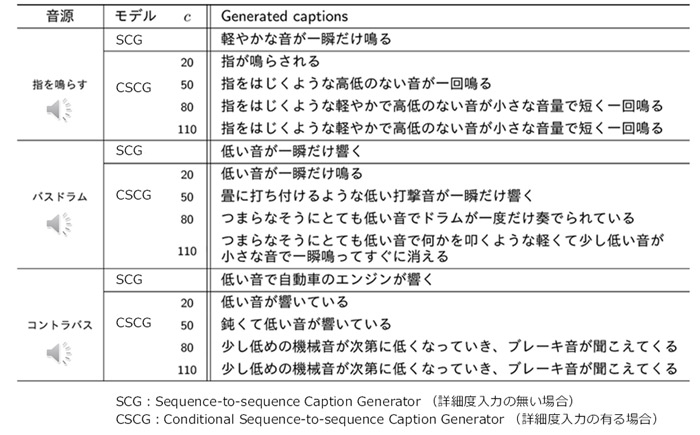
同技術による説明文の生成例
(4)「聞こえ方」の近さに基づく「音の検索」
NTTは、様々な応用が可能と考えられる同技術の一つとして「音の検索」を挙げている。
従来、効果音などの音響データの検索は、対象となる音に対して事前にテキストタグを付けて検索するのが一般的だが、タグ付けに手間が掛かる上、付けられたテキストタグだけではどのような音かが分かりにくい等、検索結果から望みの音を探すために、幾つもの検索結果の音を実際に聞いて判断する必要があった。
対して、この技術では、事前にテキストのタグ付けなしで、潜在空間の近傍探索によって、擬音語や説明文を問合せる音響データベースの検索が可能。
任意の詳しさで説明文の問合せができ、検索結果は潜在空間で擬音語や説明文が近い音、つまり人にとって聞こえ方が近い音どうしが近くに位置付けられるため、主観的な「聞こえ方」の近さに基づく「音の検索」が実現できると云う。
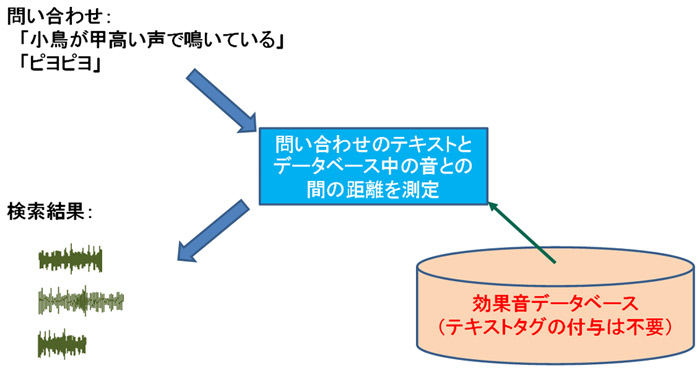
音の聞こえ方に基づく音の検索への応用例
NTTは今後、音の検索の他にも、動画音声の文字表現により動画視聴の幅の拡大や、AIが人間に近い音の感覚を身につけることで、AIと人間との日常のコミュニケーションを円滑にするなどの実現に向け、更に研究を進めていくとしている。
※5)研究協力の状況:開発の成果は、東京大学大学院情報理工学系研究科システム情報学専攻中村宏教授との共同研究の成果を含む。